常用的Spark指令
item2vec
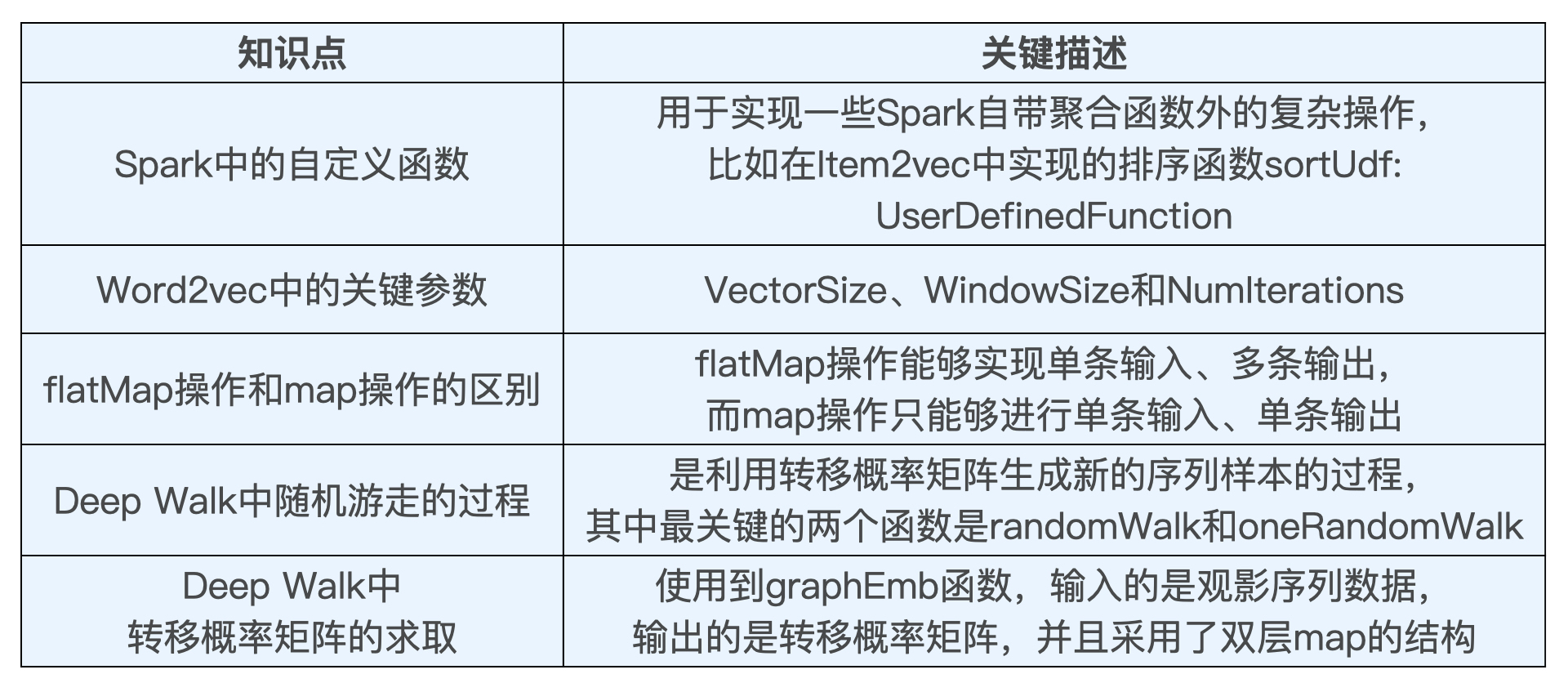
//实现一个用户定义的操作函数(UDF),用于之后的排序
//把原始的rating数据处理成序列数据
//把所有id连接成一个String,方便后续word2vec模型处理val model = word2vec.fit(samples)graph用 Spark 的 flatMap 操作把观影序列"打碎"成一个个影片对countByValue 操作统计这些影片对的数量transferMatrix(itemA)(itemB) 就是这一转移概率
Item2vec:序列数据的处理
- 读取 ratings 原始数据到 Spark 平台;
- 用 where 语句过滤评分低的评分记录;
- 用 groupBy userId 操作聚合每个用户的评分记录,DataFrame 中每条记录是一个用户的评分序列;
- 定义一个自定义操作 sortUdf,用它实现每个用户的评分记录按照时间戳进行排序;
- 把每个用户的评分记录处理成一个字符串的形式,供后续训练过程使用。
| Wiki 标记 |
|---|
!worddavd689fb673ff665ec3c587b32b6e7d4df.png|height=600,width=449!
def processItemSequence(sparkSession: SparkSession): RDD\[Seq\[String\]\] =\{
//设定rating数据的路径并用spark载入数据
val ratingsResourcesPath = this.getClass.getResource("/webroot/sampledata/ratings.csv")
val ratingSamples = sparkSession.read.format("csv").option("header", "true").load(ratingsResourcesPath.getPath)
//实现一个用户定义的操作函数(UDF),用于之后的排序
val sortUdf: UserDefinedFunction = udf((rows: Seq\[Row\]) => \{
rows.map \{ case Row(movieId: String, timestamp: String) => (movieId, timestamp) \}
.sortBy \{ case (movieId, timestamp) => timestamp \}
.map \{ case (movieId, timestamp) => movieId \}
\})
//把原始的rating数据处理成序列数据
val userSeq = ratingSamples
.where(col("rating") >= 3.5) //过滤掉评分在3.5一下的评分记录
.groupBy("userId") //按照用户id分组
.agg(sortUdf(collect_list(struct("movieId", "timestamp"))) as "movieIds") //每个用户生成一个序列并用刚才定义好的udf函数按照timestamp排序
.withColumn("movieIdStr", array_join(col("movieIds"), " "))
//把所有id连接成一个String,方便后续word2vec模型处理
//把序列数据筛选出来,丢掉其他过程数据
userSeq.select("movieIdStr").rdd.map(r => r.getAs\[String\]("movieIdStr").split(" ").toSeq) |
通过这段代码生成用户的评分序列样本中,每条样本的形式非常简单,它就是电影 ID 组成的序列,比如下面就是 ID 为 11888 用户的观影序列:296 380 344 588 593 231 595 318 480 110 253 288 47 364 377 589 410 597 539 39 160 266 350 553 337 186 736 44 158 551 293 780 353 368 858Item2vec:模型训练
| Wiki 标记 |
|---|
!worddav870600cf81b12c465e7ce052d6baf110.png|height=338,width=600!
def trainItem2vec(samples : RDD\[Seq\[String\]\]): Unit =\{
//设置模型参数
val word2vec = new Word2Vec()
.setVectorSize(10)
.setWindowSize(5)
.setNumIterations(10)
//训练模型
val model = word2vec.fit(samples)
//训练结束,用模型查找与item"592"最相似的20个item
val synonyms = model.findSynonyms("592", 20)
for((synonym, cosineSimilarity) <- synonyms) \{
println(s"$synonym $cosineSimilarity")
\}
//保存模型
val embFolderPath = this.getClass.getResource("/webroot/sampledata/")
val file = new File(embFolderPath.getPath + "embedding.txt")
val bw = new BufferedWriter(new FileWriter(file))
var id = 0
//用model.getVectors获取所有Embedding向量
for (movieId <- model.getVectors.keys)\{
id+=1
bw.write( movieId + ":" + model.getVectors(movieId).mkString(" ") + "\n")
\}
bw.close()
|
Graph Embedding:数据准备
| Wiki 标记 |
|---|
!worddav2d41b7b90ad46dd2e90c16c5e3932106.png|height=216,width=600!
//samples 输入的观影序列样本集
def graphEmb(samples : RDD\[Seq\[String\]\], sparkSession: SparkSession): Unit =\{
//通过flatMap操作把观影序列打碎成一个个影片对
val pairSamples = samples.flatMap\[String\]( sample => \{
var pairSeq = Seq\[String\]()
var previousItem:String = null
sample.foreach((element:String) => \{
if(previousItem != null)\{
pairSeq = pairSeq :+ (previousItem + ":" + element)
\}
previousItem = element
\})
pairSeq
\})
//统计影片对的数量
val pairCount = pairSamples.countByValue()
//转移概率矩阵的双层Map数据结构
val transferMatrix = scala.collection.mutable.Map\[String, scala.collection.mutable.Map\[String, Long\]\]()
val itemCount = scala.collection.mutable.Map\[String, Long\]()
//求取转移概率矩阵
pairCount.foreach( pair => \{
val pairItems = pair._1.split(":")
val count = pair._2
lognumber = lognumber + 1
println(lognumber, pair._1)
if (pairItems.length == 2)\{
val item1 = pairItems.apply(0)
val item2 = pairItems.apply(1)
if(!transferMatrix.contains(pairItems.apply(0)))\{
transferMatrix(item1) = scala.collection.mutable.Map\[String, Long\]()
\}
transferMatrix(item1)(item2) = count
itemCount(item1) = itemCount.getOrElse\[Long\](item1, 0) + count
\}
<span style="color: #333333">生成转移概率矩阵的函数输入是在训练 Item2vec 时处理好的观影序列数据。输出的是转移概率矩阵</span>
在求取转移概率矩阵的过程中,我先利用 Spark 的 flatMap 操作把观影序列"打碎"成一个个影片对,再利用 countByValue 操作统计这些影片对的数量,最后根据这些影片对的数量求取每两个影片之间的转移概率。
<span style="color: #333333">由于转移概率矩阵比较稀疏,因此我没有采用比较浪费内存的二维数组的方法,而是采用了一个双层 Map 的结构去实现它。比如说,我们要得到物品 A 到物品 B 的转移概率,那么 transferMatrix(itemA)(itemB) 就是这一转移概率。</span>
Graph Embedding:随机游走采样过程
//随机游走采样函数
//transferMatrix 转移概率矩阵
//itemCount 物品出现次数的分布
def randomWalk(transferMatrix : scala.collection.mutable.Map\[String, scala.collection.mutable.Map\[String, Long\]\], itemCount : scala.collection.mutable.Map\[String, Long\]): Seq\[Seq\[String\]\] =\{
//样本的数量
val sampleCount = 20000
//每个样本的长度
val sampleLength = 10
val samples = scala.collection.mutable.ListBuffer\[Seq\[String\]\]()
//物品出现的总次数
var itemTotalCount:Long = 0
for ((k,v) <- itemCount) itemTotalCount += v
//随机游走sampleCount次,生成sampleCount个序列样本
for( w <- 1 to sampleCount) \{
samples.append(oneRandomWalk(transferMatrix, itemCount, itemTotalCount, sampleLength))
\}
Seq(samples.toList : _*)
\}
//通过随机游走产生一个样本的过程
//transferMatrix 转移概率矩阵
//itemCount 物品出现次数的分布
//itemTotalCount 物品出现总次数
//sampleLength 每个样本的长度
def oneRandomWalk(transferMatrix : scala.collection.mutable.Map\[String, scala.collection.mutable.Map\[String, Long\]\], itemCount : scala.collection.mutable.Map\[String, Long\], itemTotalCount:Long, sampleLength:Int): Seq\[String\] =\{
val sample = scala.collection.mutable.ListBuffer\[String\]()
//决定起始点
val randomDouble = Random.nextDouble()
var firstElement = ""
var culCount:Long = 0
//根据物品出现的概率,随机决定起始点
breakable \{ for ((item, count) <- itemCount) \{
culCount += count
if (culCount >= randomDouble * itemTotalCount)\{
firstElement = item
break
\}
\}\}
sample.append(firstElement)
var curElement = firstElement
//通过随机游走产生长度为sampleLength的样本
breakable \{ for( w <- 1 until sampleLength) \{
if (!itemCount.contains(curElement) || !transferMatrix.contains(curElement))\{
break
\}
//从curElement到下一个跳的转移概率向量
val probDistribution = transferMatrix(curElement)
val curCount = itemCount(curElement)
val randomDouble = Random.nextDouble()
var culCount:Long = 0
//根据转移概率向量随机决定下一跳的物品
breakable \{ for ((item, count) <- probDistribution) \{
culCount += count
if (culCount >= randomDouble * curCount)\{
curElement = item
break
\}
\}\}
sample.append(curElement)
\}\}
Seq(sample.toList : _
<span style="color: #333333">通过随机游走产生了我们训练所需的 sampleCount 个样本之后,下面的过程就和 Item2vec 的过程完全一致了,就是把这些训练样本输入到 Word2vec 模型中,完成最终 Graph Embedding 的生成。你也可以通过同样的方法去验证一下通过 Graph Embedding 方法生成的 Embedding 的效果</span>
|